Algún día prometí que iba a hacer una versión de octopus para linux, y cumplí. Por lo menos, ya hace algo, habrá que pulirlo un poco, lógicamente.
Está escrito en Python, con una GUI en Qt y lo pueden descargar desde acá.
O, pueden mirar el código directamente gracias a pastebin:
main.py
oct.ui
octo.py
domingo, 13 de diciembre de 2009
sábado, 12 de diciembre de 2009
El funesto caso de Is y ==
Hace varios días (creo que pasaron meses) inicié una discusión en la lista de mail (creo yo, más famosa y con más gente que sabe en serio) de python. PyAr.
La cosa empezó por un artículo que leo, donde se mostraba lo siguiente:
Luego
Claro. Al ser relativamente nuevo en python, ver esto me sorprendió, por lo que decido preguntar de que se trataba en la lista.
Mi pregunta no fue del todo clara, (y acepto 100% la culpa) por lo que se entendió que mi sorpresa venia por una confusión de conceptos y que, lo que no sabía era la diferencia entre "is" y "==".
Lo que pasó:
En realidad, yo posteo todo el ejemplo (que incluye "is" y "==") para dar un contexto, pero, en si, mi sorpresa venía SOLAMENTE por ver como el operador "is" se comportaba aparentemente distinto en dos situaciones aparentemente iguales.
Noten el uso de aparentemente. Esto es:
[entero_valor_x] is [entero_valor_x]
[entero_valor_Y] is [entero_valor_Y]
False
Olvidemos que comparar enteros con "is" es una chanchada, es incorrecto y no tiene mucho sentido. Más allá de eso, no me parecía (noten que uso el tiempo pasado) que comparar enteros (del mismo valor numérico) con "is" resultara True en algunos casos y False en otros. No veia el por qué, y me parecía feo (noten que sigo usando el pasado).
Pero claro, como se interpretó mal mi pregunta, todo se enfocó a explicarme que "is" no era "==", lo cuál, no era PARA NADA el punto del topic.
Claro, fue mi culpa por no ser claro en una primera instancia. Luego, traté de remediarlo, pero ya era tarde y... el resto es historia.
La explicación:
La explicación la había encontrado muy al comienzo del thread. Posteo una que me gustó y es sencilla:
Autor: Facundo Batista
Fecha: 2009-11-04 12:192009-11-04 15:19 -300UTC
A: pyar
Asunto: Re: [pyar] WTF?
Esa es sólo una, varios usuarios lo explicaron muy bien también. =)
Y eso era todo lo que quería escuchar. Una explicación sobre el funcionamiento, en apariencia, raro del "is" comparando enteros. No que me digan que usar "is" en ese caso estaba mal (cosa que sabía) ni que "is" no es "==" (cosa que sabía), y un largo etc.
La cosa empezó por un artículo que leo, donde se mostraba lo siguiente:
>>> a = 10
>>> b = 10
>>> a == b
True
>>> a is b
True
>>> b = 10
>>> a == b
True
>>> a is b
True
Luego
>>> a = 500
>>> b = 500
>>> a == b
True
>>> a is b
False
>>> b = 500
>>> a == b
True
>>> a is b
False
Claro. Al ser relativamente nuevo en python, ver esto me sorprendió, por lo que decido preguntar de que se trataba en la lista.
Mi pregunta no fue del todo clara, (y acepto 100% la culpa) por lo que se entendió que mi sorpresa venia por una confusión de conceptos y que, lo que no sabía era la diferencia entre "is" y "==".
Lo que pasó:
En realidad, yo posteo todo el ejemplo (que incluye "is" y "==") para dar un contexto, pero, en si, mi sorpresa venía SOLAMENTE por ver como el operador "is" se comportaba aparentemente distinto en dos situaciones aparentemente iguales.
Noten el uso de aparentemente. Esto es:
True
Olvidemos que comparar enteros con "is" es una chanchada, es incorrecto y no tiene mucho sentido. Más allá de eso, no me parecía (noten que uso el tiempo pasado) que comparar enteros (del mismo valor numérico) con "is" resultara True en algunos casos y False en otros. No veia el por qué, y me parecía feo (noten que sigo usando el pasado).
Pero claro, como se interpretó mal mi pregunta, todo se enfocó a explicarme que "is" no era "==", lo cuál, no era PARA NADA el punto del topic.
Claro, fue mi culpa por no ser claro en una primera instancia. Luego, traté de remediarlo, pero ya era tarde y... el resto es historia.
La explicación:
La explicación la había encontrado muy al comienzo del thread. Posteo una que me gustó y es sencilla:
Autor: Facundo Batista
Fecha: 2009-11-04 12:192009-11-04 15:19 -300UTC
A: pyar
Asunto: Re: [pyar] WTF?
a apunta a un 3 en memoria, y b apunta al mismo 3 en memoria. Python
no creó dos objetos "3", sino que usó el mismo para los nombres a y b.
no creó dos objetos "3", sino que usó el mismo para los nombres a y b.
a apunta a un 500 en memoria, y b apunta a otro 500 en memoria. Python
sí creó dos objetos "500".
La pregunta es... ¿por qué la diferencia de comportamiento? Como bien
dijo Nati arriba, Python precachea (o tiene internalizado) algunos
enteros chicos, porque sabe que siempre se van a usar.
sí creó dos objetos "500".
La pregunta es... ¿por qué la diferencia de comportamiento? Como bien
dijo Nati arriba, Python precachea (o tiene internalizado) algunos
enteros chicos, porque sabe que siempre se van a usar.
Esa es sólo una, varios usuarios lo explicaron muy bien también. =)
Y eso era todo lo que quería escuchar. Una explicación sobre el funcionamiento, en apariencia, raro del "is" comparando enteros. No que me digan que usar "is" en ese caso estaba mal (cosa que sabía) ni que "is" no es "==" (cosa que sabía), y un largo etc.
miércoles, 18 de noviembre de 2009

sábado, 14 de noviembre de 2009
Mi Filosofía de la Programación
a) Los nombres de variables y procedimientos deben ser descriptivos, pero, lo más breves posibles. Lo mismo se aplica a nombres de tablas y campos de las mismas.
b) Los nombres de variables auxiliares deben ser más cortos aún. Si es una sola letra, mejor.
c) Todo código que se puede reutilizar se debe reutilizar.
d) Si vas a escribir 2 veces algo similar, es probable que tengas que separar ese trozo en un procedimiento aparte.
e) Es preferible que el código se explique a si mismo que escribir código ofuscado y necesitar n líneas de comentarios (salvo que genere una alta considerable en el rendimiento)
f) El CamelCase da legibilidad, pero no hay que abusar. Lo mismo se aplica al underscore.
g) Una pequeña línea de comentarios a veces ayuda mucho, pero, no abusar, si quisieramos escribir tanto seríamos escritores.
----------------------------------------------------------------------------------------------------------------------------------
Esa es mi filosofía en cuanto a la programación. Se puede estar de acuerdo o no. Paso a explicar cada punto:
a) Esto es, no usar nombre del tipo xuiud, xxsw, x45, n45. Pero tampoco utilizar nombres como NrodeCuentaBancariadelCliente. clie, nomb, arti son óptimas para variables o campos, Articulos, Clientes, VeriDeuda para tablas o procedimientos. Sentido común, yo puedo llamar a una funcion VerificarDeudaCliente, pero podría abreviarla con VeriDeuda y se seguiría entendiendo de qué se trata.
b) Si se va a usar una varible que, por ejemplo, se incrementa en una iteración el nombre tiene que se más corto aún que en a), por ejemplo: i, e, r.
c) Este punto es bastante obvio. Si ya lo pensaste ayer, reciclalo.
d) No dudar en separar código en común en una subturina o función pasandoles argumentos.
e) Eso es algo que siempre discuto. Es preferible escribir código un poco más largo en líneas pero que se entienda fácil a escribir algo ofuscado y necesitar varias líneas de comentarios para explicarlo. Esto es más obvio cuando se escribe algo hoy y se tiene que modificar en 2 o 3 meses. Ese sería el filtro.
La única excepción sería si escribirlo así me diera un rendimiento mayor y notorio.
f) Usarlos con sentido común. VeriClie o veri_clie, son aceptables. VeRiClIe o ve_ri_cli_e, es abusar.
g) Relacionado con el punto e). Agregar una línea de comentario para aclarar un poco el panorama está bien. Ahora, líneas y líneas por todos lados demuestra que algo no anda bien, por qué tu código necesita tanta explicación??
Además, si tanto te gusta escribir, capaz deberías considerar la literatura =)
jueves, 15 de octubre de 2009
CodMACs/Python
Finalmente, subí a code.google la primera versión de CodMACs (implementación escrita en python) la pueden bajar desde acá.
El zip tiene clave. La idea es tener un poco de control sobre quién bajó el script. Todavía no estoy utilizando el sistema de control de versiones que provee google.
Quién desee la clave, me puede enviar un mail a mi dirección hosteada en gmail: martincerdeira.
Edito:
Nuevo blog dedicado: http://www.codmacs.blogspot.com/

El zip tiene clave. La idea es tener un poco de control sobre quién bajó el script. Todavía no estoy utilizando el sistema de control de versiones que provee google.
Quién desee la clave, me puede enviar un mail a mi dirección hosteada en gmail: martincerdeira.
Edito:
Nuevo blog dedicado: http://www.codmacs.blogspot.com/
jueves, 8 de octubre de 2009
Microsoft Security Essentials
Principalmente, no uso antivirus por motivos obvios, pero lo que más me llamó la atención es (no se si el producto es bueno o no) la foto de la página principal, la cuál, no tiene que ver con nada.
La pueden ver acá
Y, les dejo una que propongo yo y que, a mi entender, es mucho mejor.

(click en la imagen para agrandarla)
La pueden ver acá
Y, les dejo una que propongo yo y que, a mi entender, es mucho mejor.

(click en la imagen para agrandarla)
domingo, 27 de septiembre de 2009











miércoles, 23 de septiembre de 2009
Welcome to HELL
Esto es un mail que me envió la gente de la empresa C****** con respecto a una implementación de un sistema de mensajes mediante xml con una Clínica.
Más abajo, mi respuesta.
From: ***
To: 'Martín Cerdeira'
Sent: Wednesday, September 23, 2009 11:57 AM
Subject: RV: Implementacion Integracion
Martin, como estas?
Un temita que observo, la fecha origen, que me mandan en los mensajes siempre es unos minutos ANTES de la fecha diferida (que seria la fecha de atención)
Se supone que deberia ser posterior….ya que no se cargan atenciones futuras, se cargan las que se realizaron pasadas de la fecha actual (origen)
Esto lo podrás controlar?
Siempre deberia ser posterior la fecha diferida que la fecha origen.
Gracias martin!
De: Martín Cerdeira
Enviado el: miércoles, 23 de septiembre de 2009 13:00
Para: *********
Asunto: Re: Implementacion Integracion
En el mail me decis que la Fecha Origen la mandan anterior a la Fecha Diferida:
"Un temita que observo, la fecha origen, que me mandan en los mensajes siempre es unos minutos ANTES de la fecha diferida (que seria la fecha de atención)"
O sea, FechaOrigen < Fecha Diferida.
Después me decís que la FechaDiferida debería ser posterior a la FechaOrigen:
"Siempre deberia ser posterior la fecha diferida que la fecha origen"
O sea, FechaDiferida > FechaOrigen
Luego, (FechaDiferida > FechaOrigen) = (FechaOrigen < FechaDiferida)
Esto es exactamente lo mismo pero dicho de distintas formas. Cómo es entonces?
1) FechaDiferida > FechaOrigen
2) FechaDiferida < FechaOrigen
1 o 2?
Más abajo, mi respuesta.
From: ***
To: 'Martín Cerdeira'
Sent: Wednesday, September 23, 2009 11:57 AM
Subject: RV: Implementacion Integracion
Martin, como estas?
Un temita que observo, la fecha origen, que me mandan en los mensajes siempre es unos minutos ANTES de la fecha diferida (que seria la fecha de atención)
Se supone que deberia ser posterior….ya que no se cargan atenciones futuras, se cargan las que se realizaron pasadas de la fecha actual (origen)
Esto lo podrás controlar?
Siempre deberia ser posterior la fecha diferida que la fecha origen.
Gracias martin!
De: Martín Cerdeira
Enviado el: miércoles, 23 de septiembre de 2009 13:00
Para: *********
Asunto: Re: Implementacion Integracion
En el mail me decis que la Fecha Origen la mandan anterior a la Fecha Diferida:
"Un temita que observo, la fecha origen, que me mandan en los mensajes siempre es unos minutos ANTES de la fecha diferida (que seria la fecha de atención)"
O sea, FechaOrigen < Fecha Diferida.
Después me decís que la FechaDiferida debería ser posterior a la FechaOrigen:
"Siempre deberia ser posterior la fecha diferida que la fecha origen"
O sea, FechaDiferida > FechaOrigen
Luego, (FechaDiferida > FechaOrigen) = (FechaOrigen < FechaDiferida)
Esto es exactamente lo mismo pero dicho de distintas formas. Cómo es entonces?
1) FechaDiferida > FechaOrigen
2) FechaDiferida < FechaOrigen
1 o 2?
lunes, 14 de septiembre de 2009
AFIP: Chorros Inmundos
Dando vueltas en foros y demás me encuentro con que, AFIP (conocerán los horripilantes aplicativos de estos muchachos) no contentos con el proveer ese software tan pedorro y solamente disponible para plataformas privativas (windows), además, VIOLAN la licencia GPL.
En las fuentes que cito al pie se puede ver lo que comento.
Reproduzco un mail que se les envió y su posterior respuesta:
De mi mayor consideración: Me dirijo a Ud., a los efectos de informarle que he tomado conocimiento que en la librería: “filewin.dll en la posición de
memoria 18F70 / filewin2.dll en la posición de memoria 19480/ fil14.dll “ en la posición de memoria 18F70, figura el texto: “Copyright (C) 1992-1993 Jean-loup Gailly This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 675 Mass Ave, Cambrid”
En consecuencia, y en el entendimiento de que se trata de una licencia GPL v2, la que obliga a mantener dentro del ámbito publico, distribuir con código fuente y Texto por separado de esta licencia, entre otras cosas; es que vengo por la presente a solicitarle a Ud. tenga a bien facilitarme un link para la descarga del fuente del aplicativo S.I.Ap y todos sus módulos para el uso y mantenimiento del mismo, así como para la realización de la documentación pertinente.
A tales efectos, solicito se sirva indicarme los pasos a seguir para poder acceder a dicha información.
Asimismo, solicito que en los paquetes de descarga del aplicativo y sus módulos introduzca el texto de la Licencia original para el conocimiento de la comunidad.
Sin más saludo a Ud. muy atentamente.-
EDITADO:
Cuando se les pregunta por soporte para linux o por el código fuente responden:
A quien corresponda:
Le informo que los aplicativos de la AFIP están homologados
únicamente para funcionar con las plataformas Windows 95. 98 y NT. Y
en cuanto al código fuente nos es imposible suministrarselo por razones
de seguridad.
Muchas Gracias
Saluda Atte. Mesa de Ayuda
FUENTES:
http://www.vialibre.org.ar/2008/01/28/objeciones-a-siap/
http://www.trucholand.com.ar/blog/?p=108
En las fuentes que cito al pie se puede ver lo que comento.
Reproduzco un mail que se les envió y su posterior respuesta:
De mi mayor consideración: Me dirijo a Ud., a los efectos de informarle que he tomado conocimiento que en la librería: “filewin.dll en la posición de
memoria 18F70 / filewin2.dll en la posición de memoria 19480/ fil14.dll “ en la posición de memoria 18F70, figura el texto: “Copyright (C) 1992-1993 Jean-loup Gailly This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 675 Mass Ave, Cambrid”
En consecuencia, y en el entendimiento de que se trata de una licencia GPL v2, la que obliga a mantener dentro del ámbito publico, distribuir con código fuente y Texto por separado de esta licencia, entre otras cosas; es que vengo por la presente a solicitarle a Ud. tenga a bien facilitarme un link para la descarga del fuente del aplicativo S.I.Ap y todos sus módulos para el uso y mantenimiento del mismo, así como para la realización de la documentación pertinente.
A tales efectos, solicito se sirva indicarme los pasos a seguir para poder acceder a dicha información.
Asimismo, solicito que en los paquetes de descarga del aplicativo y sus módulos introduzca el texto de la Licencia original para el conocimiento de la comunidad.
Sin más saludo a Ud. muy atentamente.-
EDITADO:
Cuando se les pregunta por soporte para linux o por el código fuente responden:
A quien corresponda:
Le informo que los aplicativos de la AFIP están homologados
únicamente para funcionar con las plataformas Windows 95. 98 y NT. Y
en cuanto al código fuente nos es imposible suministrarselo por razones
de seguridad.
Muchas Gracias
Saluda Atte. Mesa de Ayuda
FUENTES:
http://www.vialibre.org.ar/
http://www.trucholand.com.ar/
viernes, 4 de septiembre de 2009
CodMACs: Una aplicación que programa por vos (Parte 2)
CodMACs era una "buena" idea. Ahora, el tiempo que me llevaban programar el parser del lenguaje de macros que desarrollé sumado a un comentario que me hicieron en un foro[1] me llevó a pensar en una alternativa:
Qué tal si en vez de usar un lenguaje especial de macros utilizo uno más potente, ya desarrollado y que funciona? Por ejemplo, Python o PHP.
Entonces, la idea sigue siendo la misma pero, en vez de usar un lenguaje propio, utilizo un lenguaje de script mucho más poderoso y, lo más importante, conocido por muchos y totalmente funcional (al mío le faltaba muchísimo debug).
Entonces, combinandolo con lo que sería una especie de tags:
...code...code...code...code...code...code...
code...code...code...code...code...code...
code...code...code...code...code...code...
code...code...code...code...code...code...
code...code...code...code...code...code...
Donde, "...code" es el código fuente que sea. Esto generaría una salida con el código de "...code" y el resultado de evaluar el código de python entre los tags.
La idea es algo similar a lo que hace php.
Veremos.
[1] El comentario fue:
"Si yo uso eso, paso de una tarea engorrosa (programar) a tener que hacer otra aún más engorrosa (escribir las macros)"
Qué tal si en vez de usar un lenguaje especial de macros utilizo uno más potente, ya desarrollado y que funciona? Por ejemplo, Python o PHP.
Entonces, la idea sigue siendo la misma pero, en vez de usar un lenguaje propio, utilizo un lenguaje de script mucho más poderoso y, lo más importante, conocido por muchos y totalmente funcional (al mío le faltaba muchísimo debug).
Entonces, combinandolo con lo que sería una especie de tags:
...code...code...code...code...code...code...
code...code...code...code...code...code...
code...code...code...code...code...code...
<script_template_python>...code...code...code...code...code...code...
if(a==1):
print "hola"
</script_template_python>
code...code...code...code...code...code...
code...code...code...code...code...code...
Donde, "...code" es el código fuente que sea. Esto generaría una salida con el código de "...code" y el resultado de evaluar el código de python entre los tags.
La idea es algo similar a lo que hace php.
Veremos.
[1] El comentario fue:
"Si yo uso eso, paso de una tarea engorrosa (programar) a tener que hacer otra aún más engorrosa (escribir las macros)"
lunes, 31 de agosto de 2009

sábado, 22 de agosto de 2009
Problemas Abiertos de la Informática
Pensando en los famosos "problemas abiertos de las matemáticas", me puse a buscar un paralelo informático y, aquí está:
Problemas Abiertos
Problemas Abiertos
martes, 18 de agosto de 2009


lunes, 10 de agosto de 2009
Porqué Python?
Python es un lenguaje sencillo y versátil que todo el mundo (inclusive quienes no trabajen directamente en programación) debería conocer.
Posee:
- Sintaxis limpia y sencilla. Esto hace que sea rápido desarrollar reduciendo los tiempos y la cantidad necesaria de programadores. Es ideal para escritura de scripts rápidos.
- Baterías incluidas: Tiene una enorme biblioteca estándar lo que hace que el trabajo sea más veloz y sencillo.
- Multiparadigma.
- Poderoso y robusto.
- Su identación obligatoria hace que la claridad de los programas resalte.
- Usado en conjunto con bibliotecas gráficas (como GTK+ o Qt) es posible armar proyectos grandes que incluyan GUIs.
- Portable. Es posible ejecutarlo en, por ejemplo, Linux, windows y Mac, Windows Mobile, y Google Android (gracias Fisa)
- Documentación altamente disponible: 1) En internet (muchas páginas y wikis incluyendo oficiales y no oficiales) 2) Listas de correo (como pyar) donde hay un feedback constante. 3) En el mismo modo interactivo.
- Una comunidad excelente en Argentina (gracias Facundo) http://www.python.org.ar
Creo que esas son las principales.
La pregunta es, todavía no probaste python?
miércoles, 29 de julio de 2009
Conjetura de Collatz:: 3n+1
Explicación
Por si no les dió ganas de leer, basicamente lo que expone es que dado un numero entero positivo cualquiera (n), si se le realizan una serie operaciones sucesivas (si el nro es par, se lo divide por 2, caso contrario, se lo multiplica por 3 y se le suma 1) el resultado siempre es 1.
Ejemplo:
{7,22,11,34,17,52,26,13,40,20,10,5,16,8,4,2,1}
Una vez alcanzado el 1, no se continúa ya que quedaríamos en un loop ya que 1 es impar y:
1 * 3 + 1 = 4
4 / 2 = 2
2 / 2 = 1
1 * 3 + 1 = 4
etc
etc
Hasta la fecha no se ha demostrado.
Dejo un script en python que (si bien no lo demuestra) sirve para jugar un rato probando con distintos números.
Por si no les dió ganas de leer, basicamente lo que expone es que dado un numero entero positivo cualquiera (n), si se le realizan una serie operaciones sucesivas (si el nro es par, se lo divide por 2, caso contrario, se lo multiplica por 3 y se le suma 1) el resultado siempre es 1.
Ejemplo:
{7,22,11,34,17,52,26,13,40,20,10,5,16,8,4,2,1}
Una vez alcanzado el 1, no se continúa ya que quedaríamos en un loop ya que 1 es impar y:
1 * 3 + 1 = 4
4 / 2 = 2
2 / 2 = 1
1 * 3 + 1 = 4
etc
etc
Hasta la fecha no se ha demostrado.
Dejo un script en python que (si bien no lo demuestra) sirve para jugar un rato probando con distintos números.
def syracusse(init):
print "<--START (" + str(init) + ")"
syr = init
while syr != 1:
if syr % 2 == 0:
syr = syr / 2
else:
syr = (syr * 3) + 1
print syr
print "<--END"
lunes, 27 de julio de 2009
Autodocumentación
Algo muy bueno y que realmente puede ser muy útil en python es la autodocumentación.
Realmente no requiere demasiada explicación, solamente es necesario ingresar un comentario del tipo (""") al comienzo de nuestra function (debe estar identada) y luego, invocando el comando help() pasandole el nombre la función veremos ese texto. Ejemplo:
def autodoc(msj):
"""Ejemplo de autodocumentacion
parametros: msj = Mensaje a mostrar"""
print msj
help(autodoc)
Vamos a ver algo asi:
Help on function autodoc in module __main__:
autodoc(msj)
····Ejemplo de autodocumentacion
····parametros: msj = Mensaje a mostrar
(END)
sábado, 25 de julio de 2009
Crawling
Quería compartir una function de mi autoría escrita en php. Lo que hace es recorrer directorios recursivamente a partir de un path inicial.
Se llama crawleo por una particular obsesión con la palabra "jaleo". Jaleo, Crawleo... etc.
Yo uso llamo a una function (mia también) que se llama indexme. Lo que hace es indexar el contenido de los archivos en MySQL. No es relevante para el ejemplo asi que no la inclui.
Donde dice indexme pueden poner otra cosa :P
function crawleo($spath){
if(file_exists($spath)){
$ptr = opendir($spath);
while(($buf = readdir($ptr))!=null){
if(trim($buf)!="." && trim($buf)!=".."){
if(is_file($spath."\\".$buf)){
$currf = $spath."\\".$buf;
indexme($currf);
}elseif(is_dir($spath."\\".$buf)){
$currf = $spath."\\".$buf;
crawleo($currf);
}
}
}
closedir($ptr);
}else{
echo "Search Path: $spath not found";
}
}
Octopus Project
Esta entrada es sólo para decir que mi proyecto Octopus project se está pasando a linux de la mano de python.
Code name Octopys??? Pyctopus?? En fin...
Code name Octopys??? Pyctopus?? En fin...

miércoles, 22 de julio de 2009

viernes, 17 de julio de 2009
Teorema que demuestra que está todo inventado

Cuando pensé en publicar esto no supe si ponerle como título "La máquina cuantica" o "Teorema que demuestra que está todo inventado" Me decidí por el segundo porque me pareció mas gracioso.
Estaba pensando (cosa rara) acerca de las combinaciones posibles y se me vino a la mente cierto experimento mental:
Supongamos que tengo un programa que genera todas las combinaciones posibles (de todos los valores ASCII posibles) y de todos los tamaños posibles, es decir, 0 hasta X.
Antes de seguir, propongo que lean esto:
Infinitos Monos con Maquinas de Escribir
Bien, entonces, pensemos de nuevo en lo que escribí más arriba.
Tenemos un programa corriendo que genera un archivo con todas las combinaciones posibles de caracteres ASCII iniciando en un tamaño de archivo y progresando el tamaño de 1 en 1 hasta agotar las combinaciones.
Sería logico pensar que, en algún momento, algunas de las combinaciones resultantes van a resultar en un archivo de texto legible o en imagenes o en videos o en programas ejecutables, etc.
La cantidad de combinaciones es monstruosa y que seria casi imposible separar que archivo es "algo" y que es "basura". Ademas, la velocidad de procesamiento hace que sea casi interminable, faltarían vidas enteras para analizar toda la data generada y, la mayoría será "basura"
Pero, olvidemos por un momento estos pormenores, suponiendo que logré todas las combinaciones posibles desde 0 a 1GB. Y supongamos que, con algun metodo, separé lo que es basura de lo que es "algo" y lo clasifiqué en:
- Imagenes (jpg, bmp, gif, etc)
- Peliculas (avi, mov, mpeg, etc)
- Musica (mp3, wav, etc)
- Texto
Esto quiere decir que, si tengo todas las combinaciones posibles tendré, todo lo que esté en el rango de 0 a 1GB. O sea, si el tema "Welcome to the Jungle" en formato mp3 pesara 5MB, estaría allí! Lo mismo, si la película "Sin City" en formato avi pesara 780MB, también estaría allí! Loco?
Más loco: también estarían las fotos (si están en el rango de 0 a 1GB) de mis vacaciones y de las tuyas (lector)
Más escalofriante: también encontraríamos música que nunca fue escrita, peliculas que nunca fueron filmadas, textos y programas jamás escritos! De hecho, habría fotos de nosotros en situaciones que jamás pasaron con gente que ni conocemos!! De hecho, si estuviera en el rango 0 a 1GB, el código fuente del windows vista también estaría allí...
De hecho, este artículo también estaría allí.
Entonces, será que todo en realidad ya existe? O sea, ya existe en cuanto al abanico de lo potencial. No será que cuando sacamos una foto, escribimos algo, filmamos un video, etc, no estamos "creando" sino que estamos "descubriendo", "eligiendo" de una lista casi infinita de posibilidades?
Que pasaría si se pudiera llevar a cabo algo así? Supongamos que tuvieramos computadoras muchisimo mas potentes, capaces de analizar y manejar esa tremenda cantidad de datos. Que pasaría? Estaría, realmente, todo "inventado"?

martes, 7 de julio de 2009
Kit Anti Zombies
KIT ANTI-ZOMBIE 2000

Nadie es ajeno a los tiempos que corren: pandemias, virus, etc. Nunca se sabe cuando todo puede degenerar en zombies atacandonos y deseando nuestros cerebros. Es por eso que desarrollé el kit anti zombie para estar preparados.
El mismo incluye:
- Máscara de gas. Especial para mantenerse a salvo del contagio
- Escopeta recortada. Ideal para volar cabezas zombies, muy portable y comoda. (municiones no incluidas)
- 150 latas de conserva con alimentos varios. Necesario si se tiene que estar días sin salir a la calle.
- 2 walkie-talkies para comunicarte con tu compañero/a sobreviviente.
- 500 historietas de Mafalda. Es necesario un poco de humor para pasar el rato. Ademas, reir, levanta la moral.
- 1 botella de Vodka. Por su composicion quimica es ideal para fabricar cocteles Molotov y arrojarselo a los reanimados. O en su defecto, empedarse para olvidar. Tambien es util para cauterizar heridas (pero es mejor empedarse).
- Peine o peineta. Porque, vamos, habrá zombies, será el apocalipsis pero no hay razón por la cuál no verse bien.
- Soga. Los usos posibles son miles. Muy útil para colgarse en caso de desesperación.
- Cuchillo de combate (onda rambo). Idem anterior. Además es vital para traicionar a tu compañero/a sobreviviente en caso de escasez de alimentos.
- Cd y reproductor de Cds con el tema thriller de MJ (r.i.p.). Sirve para generar ambiente, además, a los zombies parece gustarles y quizá sea un buen medio de distracción.
- 2 granadas de manos. La utilidad es obvia. También es útil para suicidios masivos.
El kit es personalizable a gusto del cliente. Los precios varían según el combo elegido y se puede encagar por teléfono al 444-5584
EDITADO: Vodka agregado a pedido de Gustavox.

Nadie es ajeno a los tiempos que corren: pandemias, virus, etc. Nunca se sabe cuando todo puede degenerar en zombies atacandonos y deseando nuestros cerebros. Es por eso que desarrollé el kit anti zombie para estar preparados.
El mismo incluye:
- Máscara de gas. Especial para mantenerse a salvo del contagio
- Escopeta recortada. Ideal para volar cabezas zombies, muy portable y comoda. (municiones no incluidas)
- 150 latas de conserva con alimentos varios. Necesario si se tiene que estar días sin salir a la calle.
- 2 walkie-talkies para comunicarte con tu compañero/a sobreviviente.
- 500 historietas de Mafalda. Es necesario un poco de humor para pasar el rato. Ademas, reir, levanta la moral.
- 1 botella de Vodka. Por su composicion quimica es ideal para fabricar cocteles Molotov y arrojarselo a los reanimados. O en su defecto, empedarse para olvidar. Tambien es util para cauterizar heridas (pero es mejor empedarse).
- Peine o peineta. Porque, vamos, habrá zombies, será el apocalipsis pero no hay razón por la cuál no verse bien.
- Soga. Los usos posibles son miles. Muy útil para colgarse en caso de desesperación.
- Cuchillo de combate (onda rambo). Idem anterior. Además es vital para traicionar a tu compañero/a sobreviviente en caso de escasez de alimentos.
- Cd y reproductor de Cds con el tema thriller de MJ (r.i.p.). Sirve para generar ambiente, además, a los zombies parece gustarles y quizá sea un buen medio de distracción.
- 2 granadas de manos. La utilidad es obvia. También es útil para suicidios masivos.
El kit es personalizable a gusto del cliente. Los precios varían según el combo elegido y se puede encagar por teléfono al 444-5584
EDITADO: Vodka agregado a pedido de Gustavox.
miércoles, 3 de junio de 2009
Inicio "lento" en Debian 5 (Lenny)
Tengo Debian Lenny y me encontré con un problemita (no es grave para nada, pero me gustaría compartir la solución)
Resulta que cuando iniciaba tardaba un poco. Quedaba como frizado en dos lugares, que son:
Y después en:
Buscando (googleando) encontré como deshabilitar esos (y otros) servicios que quizá no usemos. En mi caso, cupsd (es un servicio de impresión) no tenia uso. El MTA (un servicio relacionado con el mail) tampoco.
Más info:
MTA
cupsd
El procedimiento es simple:
1) cd a /etc/rc2.d
2) Hacer un mv Snombre Knombre.
Ejemplo:
Ahora Lenny inicia en segundos.
Resulta que cuando iniciaba tardaba un poco. Quedaba como frizado en dos lugares, que son:
Código:
Starting Common Unix Printing System: cupsd.
Código:
Starting MTA
Más info:
MTA
cupsd
El procedimiento es simple:
1) cd a /etc/rc2.d
2) Hacer un mv Snombre Knombre.
Ejemplo:
Código:
mv S50exim4 K50exim4
Cómo usar PHP como lenguaje de script de consola?
El otro día programando una aplicación web (en PHP) que tenía, por un lado, una búsqueda hecha en PHP con MySQL y por otro lado necesitaba de un daemon. Éste es quién recolectaría la info y la guardaría en MySQL.
Me dispuse a escribirlo y pensé en Perl o Python (por tener algo de portabilidad windows/linux) , pero luego, lo pensé y me pregunté:
Ya que tengo php, no lo puedo usar como lenguaje de script de consola??? La respuesta es SI.
En Linux:
Instalar el intérprete
Luego armamos el archivo con un hashbang al comienzo como cualquier otro script (#!)
Ejemplo:
Listo. Al ejecutarlo nos devolverá la salida "Esto es una prueba".
En Windows:
En mi caso uso phptriad y el path al php está en:
Entonces, puedo armar un bat (por ejemplo) y llamar a mi script así:
Es decir, con cd me paré en el directorio del php.exe. Con php -f le pasé como parámetro el script que está en pru.sh. -f es para decirle que queremos parsear un file.
Hay otro métodos (por ejemplo, agregar el path del PHP a la variable de entorno path)
Agrego un link interesante:
Instalación y configuración básica de LAMP en Debian
LAMP = Linux Apache MySQL PHP (o perl o python)
Qué es LAMP?
Me dispuse a escribirlo y pensé en Perl o Python (por tener algo de portabilidad windows/linux) , pero luego, lo pensé y me pregunté:
Ya que tengo php, no lo puedo usar como lenguaje de script de consola??? La respuesta es SI.
En Linux:
Instalar el intérprete
apt-get install php5-cli
Luego armamos el archivo con un hashbang al comienzo como cualquier otro script (#!)
Ejemplo:
#! /usr/bin/php5
Listo. Al ejecutarlo nos devolverá la salida "Esto es una prueba".
En Windows:
En mi caso uso phptriad y el path al php está en:
C:\apache\php\
Entonces, puedo armar un bat (por ejemplo) y llamar a mi script así:
cd C:\apache\php\
php -f C:\PHP\pru.sh
Es decir, con cd me paré en el directorio del php.exe. Con php -f le pasé como parámetro el script que está en pru.sh. -f es para decirle que queremos parsear un file.
Hay otro métodos (por ejemplo, agregar el path del PHP a la variable de entorno path)
Agrego un link interesante:
Instalación y configuración básica de LAMP en Debian
LAMP = Linux Apache MySQL PHP (o perl o python)
Qué es LAMP?
martes, 7 de abril de 2009
jueves, 2 de abril de 2009
CodMACs: Una aplicación que programa por vos
CodMACs
Creating an application, easily in 4 steps:
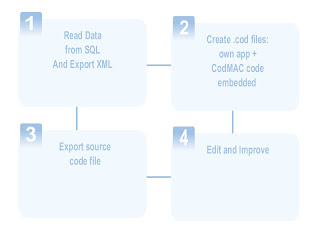
1 - Reads your database and builds the XML file (containing DataBases Structure) .
The XML file is editable. You can use plain xml or "Treeview-Like" edition.
2 - Using the Editor + Highlighter, create .COD file which contains your own source code (in any language) + the CodMAC code embedded .
3 - Based on the .COD and XML Structure files, generates automatically all the source code your application will need.
4 - Finally, you can edit the result source code.
Simple menus will allow you to accomplish all these actions easily, very quickly, increasing your productivity.
Si, parece una mentira. Pero no. Es cierto. O casi. No es que la aplicación "programe" por si sola sino que, basandose en un código fuente básico (que es la base de tus programas) + un sistema de tags y marcas embebidos dentro del mismo, se logra generar código fuente en segundos.
Por ejemplo, si uno programa en Java, el template tendría la base en dicho lenguaje y, además, el código CodMAC embebido. El programa genera un resultado que es, sencillamente código fuente en Java. Se reemplaza el código escrito en CodMAC. (así como PHP genera puro HTML, por poner un ejemplo paralelo) por el resultado en el lenguaje deseado (en este caso, Java)
Cómo funciona?? Acá es donde puedo explicarlo bien debido a que soy el desarrollador.
Muchas veces en los sistemas o programas comerciales, las aplicaciones (tipo ingresos en grid, ABMs, etc) son similares. Esto es lo que aprovecha CodMACs.
La aplicación posee tres elementos:
1- Editor de texto para templates con iluminador. Ejemplo, un programa tuyo en C con los "tags" o marcas propios de CodeMACs.
2- Información acerca de las bases de datos. Esto es necesario tenerlo en formato XML. El programa posee además un módulo de conexión (por ahora sólo con SQL server) que toma las bases de datos deseadas y genera la documentación necesaria en el formato XML.
El mismo se puede editar y visualizar de forma plana y con un editor tipo TreeView.
3- Editor de texto para "Funciones" o MACROS si se las quiere llamar así. También tiene iluminador.
Entonces, primero tomamos un pedazo de un programa nuestro. La base, digamos. Entonces, tomamos el código fuente base y, donde haya referencias a una tabla, o campos se lo reemplaza por marcas de propias de CodMACs, ya sean marcas simples, funciones o Loops. Todo eso posee CodMACs.
Detallo algunas:
@@!FileName : El nombre del archivo
@@!TableName : El nombre de la tabla
@@!Index : Un índice, sirve como contador dentro de un LOOP
@@LOOP : Marca de inicio de loop. Loopea una vez por cada campo de la tabla.
@@/LOOP: Marca de fin de loop.
Entonces, dentro de nuestro código fuente metemos estas marcas. Sería un pseudo lenguaje embebido.
Es decir que si una tabla se llama Clientes, y tiene los campos clie, nomb, cuit, en todos lados donde aparezca la marca @@!TableName se reemplazará por el nombre de la tabla, en este caso Clientes. Y si ponemos un loop así:
@@LOOP
Const C@@!Identifier as integer = @@!Index
@@/LOOP
Nos quedaría:
Const Cclie as integer = 0
Const Cnomb as integer = 1
Const Ccuit as integer = 2
Además, puede pasar que deseemos hacer algo en un caso, por ejemplo, si el campo es numérico o si el campo es de texto. Eso se resuelve con las funciones. Un ejemplo de una función:
BEGIN Function Defitipo2(Value)
CASE 'nvarchar['+* || tString
CASE 'datetime' || tsFecha
CASE 'smalldatetime' || tsFecha
CASE 'money' || tNumeric
CASE 'real' || tNumeric
CASE 'int' || tNumeric
END Defitipo2
Si el campo es int, vemos que pone tNumeric. Entonces, poniendo
@@CASE(@@!Format,Defitipo2)
Estas funciones son totalmente editables por el usuario. Es decir, pueden haber tantas como se desee y se creen en un apartado especial. Sería igual que crear funciones en cualquier lenguaje de programación.
En el ejemplo, le estamos diciendo con @@CASE que se trata de una función. Con @@!Format es que le estoy pasando ese valor a la función, y Defitipo2 es el nombre de la función. En ese caso le estaría pasando a la función DefiTipo2 el formato del campo en el que estoy. Y ya vimos lo que hace, si el campo fuera int, todo el texto
@@CASE(@@!Format,Defitipo2)
Sería reemplazado por:
tNumeric
Una vez que tenemos el "template" lo guardamos como extensión cod. Luego, generamos la documentación sobre la/s tabla/s de nuestra/s base/s de datos (en un XML). Ahora, podemos si se desea guardar el proyecto (un archivo con extensión mrt) esto nos permite en un futuro, abriendo el *.mrt, tener el xml y el cod que queramos.
Una vez que tenemos el XML y el cod, le tememos que decir al programa que nos genere un codigo fuente. Basicamente, se elige las tablas que queremos, la extensión que deseamos y listo.
La estructura que usé en el XML es muy simple.
Postearé un video y, cuando esté más maduro, la primera beta. Ahora, dejo unos screenshots del CodeMAcs trabajando. En este caso se puede ver código fuente en VB6 con código de CodMACs embebido.
Saludos
ScreenShots:

Comparación de código fuente generado(visto en notepad) contra el código que lo generó dentro de CodMACs.
Se puede ver como un loop cambió por una lista grande de los campos.

CodeMACs guardando un archivo frm generado desde un template.

Selector de tablas. En este caso hay una sola.

Editor de Funciones.

Vista de XML

Editor de templates con menu de ayuda(insertando tags)

Icono principal de la aplicación.
Web Oficial: http://codmacs.tk
Creating an application, easily in 4 steps:

1 - Reads your database and builds the XML file (containing DataBases Structure) .
The XML file is editable. You can use plain xml or "Treeview-Like" edition.
2 - Using the Editor + Highlighter, create .COD file which contains your own source code (in any language) + the CodMAC code embedded .
3 - Based on the .COD and XML Structure files, generates automatically all the source code your application will need.
4 - Finally, you can edit the result source code.
Simple menus will allow you to accomplish all these actions easily, very quickly, increasing your productivity.
Si, parece una mentira. Pero no. Es cierto. O casi. No es que la aplicación "programe" por si sola sino que, basandose en un código fuente básico (que es la base de tus programas) + un sistema de tags y marcas embebidos dentro del mismo, se logra generar código fuente en segundos.
Por ejemplo, si uno programa en Java, el template tendría la base en dicho lenguaje y, además, el código CodMAC embebido. El programa genera un resultado que es, sencillamente código fuente en Java. Se reemplaza el código escrito en CodMAC. (así como PHP genera puro HTML, por poner un ejemplo paralelo) por el resultado en el lenguaje deseado (en este caso, Java)
Cómo funciona?? Acá es donde puedo explicarlo bien debido a que soy el desarrollador.
Muchas veces en los sistemas o programas comerciales, las aplicaciones (tipo ingresos en grid, ABMs, etc) son similares. Esto es lo que aprovecha CodMACs.
La aplicación posee tres elementos:
1- Editor de texto para templates con iluminador. Ejemplo, un programa tuyo en C con los "tags" o marcas propios de CodeMACs.
2- Información acerca de las bases de datos. Esto es necesario tenerlo en formato XML. El programa posee además un módulo de conexión (por ahora sólo con SQL server) que toma las bases de datos deseadas y genera la documentación necesaria en el formato XML.
El mismo se puede editar y visualizar de forma plana y con un editor tipo TreeView.
3- Editor de texto para "Funciones" o MACROS si se las quiere llamar así. También tiene iluminador.
Entonces, primero tomamos un pedazo de un programa nuestro. La base, digamos. Entonces, tomamos el código fuente base y, donde haya referencias a una tabla, o campos se lo reemplaza por marcas de propias de CodMACs, ya sean marcas simples, funciones o Loops. Todo eso posee CodMACs.
Detallo algunas:
@@!FileName : El nombre del archivo
@@!TableName : El nombre de la tabla
@@!Index : Un índice, sirve como contador dentro de un LOOP
@@LOOP : Marca de inicio de loop. Loopea una vez por cada campo de la tabla.
@@/LOOP: Marca de fin de loop.
Entonces, dentro de nuestro código fuente metemos estas marcas. Sería un pseudo lenguaje embebido.
Es decir que si una tabla se llama Clientes, y tiene los campos clie, nomb, cuit, en todos lados donde aparezca la marca @@!TableName se reemplazará por el nombre de la tabla, en este caso Clientes. Y si ponemos un loop así:
@@LOOP
Const C@@!Identifier as integer = @@!Index
@@/LOOP
Nos quedaría:
Const Cclie as integer = 0
Const Cnomb as integer = 1
Const Ccuit as integer = 2
Además, puede pasar que deseemos hacer algo en un caso, por ejemplo, si el campo es numérico o si el campo es de texto. Eso se resuelve con las funciones. Un ejemplo de una función:
BEGIN Function Defitipo2(Value)
CASE 'nvarchar['+* || tString
CASE 'datetime' || tsFecha
CASE 'smalldatetime' || tsFecha
CASE 'money' || tNumeric
CASE 'real' || tNumeric
CASE 'int' || tNumeric
END Defitipo2
Si el campo es int, vemos que pone tNumeric. Entonces, poniendo
@@CASE(@@!Format,Defitipo2)
Estas funciones son totalmente editables por el usuario. Es decir, pueden haber tantas como se desee y se creen en un apartado especial. Sería igual que crear funciones en cualquier lenguaje de programación.
En el ejemplo, le estamos diciendo con @@CASE que se trata de una función. Con @@!Format es que le estoy pasando ese valor a la función, y Defitipo2 es el nombre de la función. En ese caso le estaría pasando a la función DefiTipo2 el formato del campo en el que estoy. Y ya vimos lo que hace, si el campo fuera int, todo el texto
@@CASE(@@!Format,Defitipo2)
Sería reemplazado por:
tNumeric
Una vez que tenemos el "template" lo guardamos como extensión cod. Luego, generamos la documentación sobre la/s tabla/s de nuestra/s base/s de datos (en un XML). Ahora, podemos si se desea guardar el proyecto (un archivo con extensión mrt) esto nos permite en un futuro, abriendo el *.mrt, tener el xml y el cod que queramos.
Una vez que tenemos el XML y el cod, le tememos que decir al programa que nos genere un codigo fuente. Basicamente, se elige las tablas que queremos, la extensión que deseamos y listo.
La estructura que usé en el XML es muy simple.
Postearé un video y, cuando esté más maduro, la primera beta. Ahora, dejo unos screenshots del CodeMAcs trabajando. En este caso se puede ver código fuente en VB6 con código de CodMACs embebido.
Saludos
ScreenShots:

Comparación de código fuente generado(visto en notepad) contra el código que lo generó dentro de CodMACs.
Se puede ver como un loop cambió por una lista grande de los campos.

CodeMACs guardando un archivo frm generado desde un template.

Selector de tablas. En este caso hay una sola.

Editor de Funciones.

Vista de XML

Editor de templates con menu de ayuda(insertando tags)

Icono principal de la aplicación.
Web Oficial: http://codmacs.tk
lunes, 30 de marzo de 2009
Sobre el IQ
Hace rato que tenia ganas de escribir sobre esto. Cuantas veces uno ha oído "tal persona tiene tanto de IQ" o "determinado personaje posee un coeficiente intelectual de X"
Ahora, alguna vez uno se planteó qué es un IQ??
Según wikipedia el IQ es un resultado de un test:
La primera vez que me enteré de la existencia de esto (tendría unos 15 años) me pareció interesante, anque simplista voy a reconocer. Simplista para ser algo que "define" la inteligencia. O sea, vendría a ser, X individuo hace un test que consiste en N numero de preguntas (de logica, reconocimiento de series, patrones) y dependendiendo de como le vaya, es cuan inteligente es esa persona. Muy chato para mi gusto. Sin envargo realicé varios tests por curiosidad. No recuerdo los resultados (seguramente me salió que estoy en la media) pero lo que si recuerdo es que, siendo distintos los tests, hacer el primero me fue mas dificil que el segundo. Esto es, el hacer el primero me "entrenó" de alguna forma. Hizo que hacer el segundo fuera más sencillo, además de que sabía que esperar (a pesar de que los tests no eran iguales) me había mostrado una forma encarar ciertos problemas. Entonces, hice algunos más y noté que era como si justamente fuera un entrenamiento, practicar el tipo de ejercicios hacía que los posteriores costaran un poco menos.
De todo esto se desprende mi conclusión. Los tests de IQ dan un número a la habilidad/experiencia de una persona para resolver un tipo de problema. La inteligencia no es algo "medible" y mucho menos por completar unas series de cuadraditos o de números. Estos tests sólo dividen, y estancan. Le dicen a alguien "vos sos la media" como que no hubiera más remedio.
No me hubiera atrevido a publicar esta entradad (hubiera considerado que estos son disparates míos) si no fuera por un comentario que leí en un libro de Paenza (de las serie "matematica, estás ahí?") donde él mismo opinaba algo similar a mi.
Ahora, alguna vez uno se planteó qué es un IQ??
Según wikipedia el IQ es un resultado de un test:
El cociente intelectual o coeficiente intelectual,[1] abreviado CI (en inglés IQ) es un número que resulta de la realización de un test estandarizado para medir las habilidades cognitivas de una persona, "inteligencia", en relación con su grupo de edad
La primera vez que me enteré de la existencia de esto (tendría unos 15 años) me pareció interesante, anque simplista voy a reconocer. Simplista para ser algo que "define" la inteligencia. O sea, vendría a ser, X individuo hace un test que consiste en N numero de preguntas (de logica, reconocimiento de series, patrones) y dependendiendo de como le vaya, es cuan inteligente es esa persona. Muy chato para mi gusto. Sin envargo realicé varios tests por curiosidad. No recuerdo los resultados (seguramente me salió que estoy en la media) pero lo que si recuerdo es que, siendo distintos los tests, hacer el primero me fue mas dificil que el segundo. Esto es, el hacer el primero me "entrenó" de alguna forma. Hizo que hacer el segundo fuera más sencillo, además de que sabía que esperar (a pesar de que los tests no eran iguales) me había mostrado una forma encarar ciertos problemas. Entonces, hice algunos más y noté que era como si justamente fuera un entrenamiento, practicar el tipo de ejercicios hacía que los posteriores costaran un poco menos.
De todo esto se desprende mi conclusión. Los tests de IQ dan un número a la habilidad/experiencia de una persona para resolver un tipo de problema. La inteligencia no es algo "medible" y mucho menos por completar unas series de cuadraditos o de números. Estos tests sólo dividen, y estancan. Le dicen a alguien "vos sos la media" como que no hubiera más remedio.
No me hubiera atrevido a publicar esta entradad (hubiera considerado que estos son disparates míos) si no fuera por un comentario que leí en un libro de Paenza (de las serie "matematica, estás ahí?") donde él mismo opinaba algo similar a mi.
miércoles, 25 de marzo de 2009
Estudiar Programación
Esta entrada no tiene ningún test. Sólo es para plasmar una opinión acerca de cómo se enseña (mayormente) programación en, por lo menos, Argentina.
Mejor dicho, voy a exponer como creo que se debería enseñar haciendo referencia por momentos a cómo se enseña o a aquellos aspectos que considero erróneos.
Primero, considero que los métodos tradicionales de enseñanza no son aplicables. Con esto me refiero al esquema:
Pizarrón --> Profesor --> Alumnos
Éste esquema lineal es, o puede ser, muy útil en otros ámbitos. En programación no sirve de nada. No existe tal cosa como "teóricas"(o, al menos, no debería).
El esquema que propongo es:
|----> Profesor (si se requiere)
|
alumno <--> PC
|
|-------> Google, manuales y/o pdf
Explico:
El alumno tiene una pc (una por alumno)
Al alumno se le dan tareas de programación. Es decir, se lo hace programar, subiendo en dificultad claro, pero estando en contacto con el código, debugger, y compilador (si lo hubiera) desde la primer clase.
El alumno debería tener acceso a bibliografía (puede ser impresa o material en la pc) sobre el lenguaje en cuestión. Además de google y cualquier otro medio que el profesor (o incluso el alumno) proponga.
Ante cualquier tipo de duda, el profesor debe tener el conocimiento para acercarse a la pc del alumno y ver el problema con éste.
Cada clase tiene un mini TP que hay que entregar.
Con esto logramos varias cosas:
1) Por un lado que la clase sea entretenida. Nadie quiere escuchar a un tipo hablar más de media hora.
2) El alumno comienza a programar desde la primera clase con problemas lo más reales posibles.
3) Si un alumno avanza más rápido que otro no se aburre porque va a su ritmo. Lo mismo para uno que sea más lento, no se pierde.
4) Es fácil monitorear el avance antes de un parcial o prueba.
5) El alumno se entrena en "pensar". El foco está en resolver problemas, aplicar lógicas. Memorizar la sintaxis (saber si es print, printf, sprint, etc) no sirve de mucho. Es mejor aprender a pensar lógicas, sin importar la sintaxis (para eso están las referencias del lenguaje) En todo caso, es mejor saber pensar, memorizar la sintaxis va a venir sólo con el uso mismo del lenguaje.
Cómo una excepción a lo que serían las teóricas, se podrían dedicar unas clase si es que los alumnos no poseen conocimientos de programación (es decir, si están de cero) a explicar conceptos básicos como: qué es un loop, un condicional, etc
Pero esto sólo si es necesario.
Para la evaluación, con los TP se va viendo si el alumno progresa o no (ya que son individuales)
Como final, se podría hacer un TP grande o un parcial.
En el caso de un parcial, obviamente, escrito en papel no tiene sentido (si, en algunos lados toman asi) . Mucho menos creo que haya que hacerle memorizar las sintaxis, o preguntas del tipo:
Cuántos parámetros lleva el bucle For?
Los manuales que el alumno tiene en los TP, debería tenerlos en el final o parcial. Lo importante es que sepa pensar y resolver los problemas. El memorizar la sintaxis no es, NI DEBERIA SER, la finalidad.
Para finalizar, solo quiero agregar que este esquema respondería a lo que un autodidacta haría en su casa:
- Instalar una Ide o interprete (o lo que se necesite de un lenguaje)
- Probar algo sencillo
- Programar algo mas real.
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
....
Esta es la forma de aprender de verdad. Entonces, porqué no aplicarla (de manera más controlada si se quiere) a las cátedras y/o cursos de programación?
Mejor dicho, voy a exponer como creo que se debería enseñar haciendo referencia por momentos a cómo se enseña o a aquellos aspectos que considero erróneos.
Primero, considero que los métodos tradicionales de enseñanza no son aplicables. Con esto me refiero al esquema:
Pizarrón --> Profesor --> Alumnos
Éste esquema lineal es, o puede ser, muy útil en otros ámbitos. En programación no sirve de nada. No existe tal cosa como "teóricas"(o, al menos, no debería).
El esquema que propongo es:
|----> Profesor (si se requiere)
|
alumno <--> PC
|
|-------> Google, manuales y/o pdf
Explico:
El alumno tiene una pc (una por alumno)
Al alumno se le dan tareas de programación. Es decir, se lo hace programar, subiendo en dificultad claro, pero estando en contacto con el código, debugger, y compilador (si lo hubiera) desde la primer clase.
El alumno debería tener acceso a bibliografía (puede ser impresa o material en la pc) sobre el lenguaje en cuestión. Además de google y cualquier otro medio que el profesor (o incluso el alumno) proponga.
Ante cualquier tipo de duda, el profesor debe tener el conocimiento para acercarse a la pc del alumno y ver el problema con éste.
Cada clase tiene un mini TP que hay que entregar.
Con esto logramos varias cosas:
1) Por un lado que la clase sea entretenida. Nadie quiere escuchar a un tipo hablar más de media hora.
2) El alumno comienza a programar desde la primera clase con problemas lo más reales posibles.
3) Si un alumno avanza más rápido que otro no se aburre porque va a su ritmo. Lo mismo para uno que sea más lento, no se pierde.
4) Es fácil monitorear el avance antes de un parcial o prueba.
5) El alumno se entrena en "pensar". El foco está en resolver problemas, aplicar lógicas. Memorizar la sintaxis (saber si es print, printf, sprint, etc) no sirve de mucho. Es mejor aprender a pensar lógicas, sin importar la sintaxis (para eso están las referencias del lenguaje) En todo caso, es mejor saber pensar, memorizar la sintaxis va a venir sólo con el uso mismo del lenguaje.
Cómo una excepción a lo que serían las teóricas, se podrían dedicar unas clase si es que los alumnos no poseen conocimientos de programación (es decir, si están de cero) a explicar conceptos básicos como: qué es un loop, un condicional, etc
Pero esto sólo si es necesario.
Para la evaluación, con los TP se va viendo si el alumno progresa o no (ya que son individuales)
Como final, se podría hacer un TP grande o un parcial.
En el caso de un parcial, obviamente, escrito en papel no tiene sentido (si, en algunos lados toman asi) . Mucho menos creo que haya que hacerle memorizar las sintaxis, o preguntas del tipo:
Cuántos parámetros lleva el bucle For?
Los manuales que el alumno tiene en los TP, debería tenerlos en el final o parcial. Lo importante es que sepa pensar y resolver los problemas. El memorizar la sintaxis no es, NI DEBERIA SER, la finalidad.
Para finalizar, solo quiero agregar que este esquema respondería a lo que un autodidacta haría en su casa:
- Instalar una Ide o interprete (o lo que se necesite de un lenguaje)
- Probar algo sencillo
- Programar algo mas real.
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
- Consultar un manual, manual online, google, etc
- Programar
....
Esta es la forma de aprender de verdad. Entonces, porqué no aplicarla (de manera más controlada si se quiere) a las cátedras y/o cursos de programación?
sábado, 21 de marzo de 2009
Octopus Project: Software Multiclipboard
Esto es sólo para darle un lugar a un soft mío.
http://octopusproject.tk/
En la página está todo explicado pero, basicamente, es un software que permite manejar hasta 8 clipboards.
http://octopusproject.tk/
En la página está todo explicado pero, basicamente, es un software que permite manejar hasta 8 clipboards.
viernes, 20 de marzo de 2009
Black Hole: Un link que apunta a otro
Pensando el otro día se me ocurrió probar que pasaba si un acceso directo de windows (archivo .lnk) apuntaba a otro y a su vez, ese otro apuntaba al primero.
Es decir:
A.lnk --> Apunta a B.lnk
B.lnk --> Apunta a A.lnk
Formando asi una especie de ciclo sin fin.
Obviamente, esto no se puede hacer con el sistema operativo en si, es decir, tecnicamente hablando: "el windo' no te deja, che"
Pero, con la ayuda de un editor hexa se puede lograr. El efecto (y por el cual lo nombré blackhole) es que el explorer crashea. No podés ver que hay dentro de la carpeta que los contiene.
Esto fue testeado en windows2000 y windowsXP.
En windows98... NO FALLA!!!
Aparentemente en windows Vista está corregido. La prueba que hice no falló. Quedaría ver que sucede con accesos creados en Vista, pero me imagino que es lo mismo, no va a fallar.
Procedimiento:
Antes que nada, no lo pongan en el escritorio ya que crasheará el explorer y no lo podrán arreglar mas que entrando en modo consola.
1) Crear un archivo. Digamos: C:\Prueba\A.txt
2) Generar un acceso directo al mismo. Digamos C:\Prueba\A.lnk
3) Borrar A.txt
4) Editar A.lnk con un editor HEXA. Es sencillo, van a ver varios caracteres ilegibles y, en medio de todo eso, por varios lados aparece el nombre del archivo
"C:\Prueba\A.txt" eso lo cambiamos por C:\Prueba\B.lnk
5) Copiar el A.lnk editado y pegarlo. Renombrarlo a B.lnk.
6) Abrir B.lnk. Vamos a encontrarnos que dentro apunta a B.lnk (ya que es el A.lnk editado) Reemplazamos C:\Prueba\B.lnk por C:\Prueba\A.lnk
7) Nos quedó A.lnk apuntando a B.lnk y viceversa.
8) Al entrar en la carpeta prueba usando el explorador de windows, veran como crashea.
NO me hago responsable si se les cuelga windows o algo mas desagradable pasa. En todas las pruebas que realice solo moria el explorer (y levantaba de nuevo por si solo)
Happy Testing.
Es decir:
A.lnk --> Apunta a B.lnk
B.lnk --> Apunta a A.lnk
Formando asi una especie de ciclo sin fin.
Obviamente, esto no se puede hacer con el sistema operativo en si, es decir, tecnicamente hablando: "el windo' no te deja, che"
Pero, con la ayuda de un editor hexa se puede lograr. El efecto (y por el cual lo nombré blackhole) es que el explorer crashea. No podés ver que hay dentro de la carpeta que los contiene.
Esto fue testeado en windows2000 y windowsXP.
En windows98... NO FALLA!!!
Aparentemente en windows Vista está corregido. La prueba que hice no falló. Quedaría ver que sucede con accesos creados en Vista, pero me imagino que es lo mismo, no va a fallar.
Procedimiento:
Antes que nada, no lo pongan en el escritorio ya que crasheará el explorer y no lo podrán arreglar mas que entrando en modo consola.
1) Crear un archivo. Digamos: C:\Prueba\A.txt
2) Generar un acceso directo al mismo. Digamos C:\Prueba\A.lnk
3) Borrar A.txt
4) Editar A.lnk con un editor HEXA. Es sencillo, van a ver varios caracteres ilegibles y, en medio de todo eso, por varios lados aparece el nombre del archivo
"C:\Prueba\A.txt" eso lo cambiamos por C:\Prueba\B.lnk
5) Copiar el A.lnk editado y pegarlo. Renombrarlo a B.lnk.
6) Abrir B.lnk. Vamos a encontrarnos que dentro apunta a B.lnk (ya que es el A.lnk editado) Reemplazamos C:\Prueba\B.lnk por C:\Prueba\A.lnk
7) Nos quedó A.lnk apuntando a B.lnk y viceversa.
8) Al entrar en la carpeta prueba usando el explorador de windows, veran como crashea.
NO me hago responsable si se les cuelga windows o algo mas desagradable pasa. En todas las pruebas que realice solo moria el explorer (y levantaba de nuevo por si solo)
Happy Testing.
Visual Basic 6 (testeo de compilación)
Queriendo compilar en visual basic 6 de la misma forma que en C (generando objects por separado y luego linkeandolos) encontré lo siguiente:
El tema es, el VB6 compila con un exe C2.exe y linkea con el LINK.exe
Lo que hice fue, reemplazar el C2.EXE por un exe mio, mi exe loguea los parametros que le pasa el vb6. Luego hice lo mismo con el link.exe y listo, tenia los parametros que le tengo que pasar a los dos exes.
El C2.exe crea los OBJ, el link, linkea.
Queda corregir un problema más. El vb6 genera un archivo por cada frm en un "lenguage intermedio". Se supone que es ese archivo que guarda en temporales y que genera usando el comando iL (intermediate language) Esto es una suposición mía.
El tema es, el VB6 compila con un exe C2.exe y linkea con el LINK.exe
Lo que hice fue, reemplazar el C2.EXE por un exe mio, mi exe loguea los parametros que le pasa el vb6. Luego hice lo mismo con el link.exe y listo, tenia los parametros que le tengo que pasar a los dos exes.
El C2.exe crea los OBJ, el link, linkea.
log del C2.exe-il "C:\DOCUME~1\Martin\CONFIG~1\Temp\VB375862" -f "Class1" -W 3 -Gy -G5 -Gs4096 -dos -Zl -Fo"C:\Documents and Settings\Martin\Escritorio\frmLala.OBJ" -QIfdiv -ML -basic
log del link.exe"C:\Documents and Settings\Martin\Escritorio\frmLala.OBJ" "C:\Documents and Settings\Martin\Escritorio\Proyecto.OBJ" "C:\Archivos de programa\Microsoft Visual Studio\VB98\VBAEXE6.LIB" /ENTRY:__vbaS /OUT:"C:\Documents and Settings\Martin\Escritorio\Proyecto.exe" /BASE:0x400000 /SUBSYSTEM:WINDOWS,4.0 /VERSION:1.0 /INCREMENTAL:NO /OPT:REF /MERGE:.rdata=.text /IGNORE:4078
Queda corregir un problema más. El vb6 genera un archivo por cada frm en un "lenguage intermedio". Se supone que es ese archivo que guarda en temporales y que genera usando el comando iL (intermediate language) Esto es una suposición mía.
Extensión XPI: Zips camuflados
Asi que eran zips camuflados nomás.
Viendo el xpi (extensión de firefox) de piratesoftheamazon con un editor HEXA veo la marca
PK
Al comienzo del file. "Es un zip" pienso. Le cambio la extensión y ahi lo tenía. Todos los files que usa, js, archivos de imagen, etc.
Interesante para hacer xpi propios.
Luego busqué en google, cosa que debería haber hecho antes :)
http://filext.com/file-extension/XPI
Viendo el xpi (extensión de firefox) de piratesoftheamazon con un editor HEXA veo la marca
PK
Al comienzo del file. "Es un zip" pienso. Le cambio la extensión y ahi lo tenía. Todos los files que usa, js, archivos de imagen, etc.
Interesante para hacer xpi propios.
Luego busqué en google, cosa que debería haber hecho antes :)
http://filext.com/file-extension/XPI
Suscribirse a:
Comentarios (Atom)



